Step 4 : Scalabilité / Résilience
Nous avons une infrastructure qui fonctionne, mais qui n'est pas vraiment résiliente. En effet, en ne servant tous nos services que par une instance, nous prenons un risque si la zone ou même une instance devait avoir des soucis.
Dans ce chapitre, pour améliorer notre résilience, nous allons augmenter le nombre de nos instances et les répartirons sur plusieurs zones grâce au service ASG, Auto Scaling groups, puis répartirons la charge dessus grâce au service ELB, Elastic Load Balancer.
Note
Augmenter sa résilience/fiabilité a un coût qui se jauge au vu du risque encouru.
Citation tirée du SRE Book Embracing RiskConcepts
ELB
Elastic Load Balancer, ELB, est le service permettant de répartir la charge de nos requêtes/connexions vers les services sur nos instances potentiellement réparties sur plusieurs AZs, Availability Zones.
On y configure des listeners renvoyant via des règles vers des targets groups. On enregistre nos instances dans les target groups.

Il en existe plusieurs types de load balancer, chacun opèrant à un niveau différent et permettant de faire des choses différentes :
- Gateway Load Balancer, GLB, couche OSI 3, pour des besoins spécifiques autour de sécurité/audits réseau.
- Network Load Balancer, NLB, couche OSI 4, le plus performant et seul à permettre des IPs statiques
- Application Load Balancer, ALB, couche OSI 7, authentification, redirections, path routing...
Note
Pour plus de détails et comparaisons autour des différents types voici un tableau comparatif.
Pour ce TP, nous utiliserons des ALBs.
Health Checks
Les health checks se configurent au niveau des target groups et permettent de ne servir du traffic uniquement sur les cibles saines.
Ces health check sont faits par l'ELB à une fréquence configurable. Cette fréquence influe sur la résilience globale de notre service. Une fréquence trop haute implique plus de coûts, mais une fréquence trop basse implique potentiellement plus de requêtes mal servies si une cible a des soucis.
Par défault un ALB aura un interval de 30 secondes.
Cross-zone load balancing
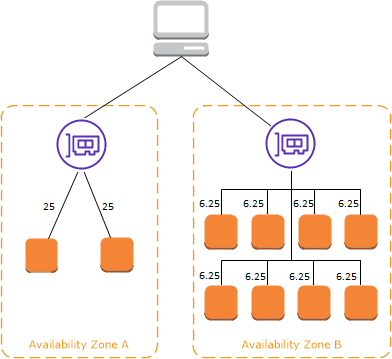
Pour chaque zone qui lui est configurée, un ELB crée une interface réseau. La charge est répartie équitablement sur les deux interfaces via DNS.
Le Cross-zone load balancing est le paramètre permettant d'indiquer à un ELB s'il doit renvoyer uniquement dans sa zone ou pas. Une fois activé, au prix de potentiels coûts réseaux interzone, la charge est équitablement répartie par chaque interface.
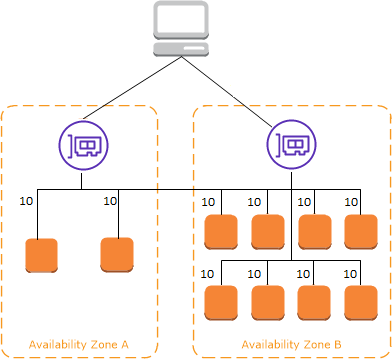
En cas de mauvaise répartition d'instances et si le Cross-zone load balancing est désactivé, on peut tomber dans des cas de ce type :
Note
Il y a beaucoup de configurations juste sur un ELB et chaqune peut avoir son importance en production
- Terminaison TLS
- Connection draining
- Sticky session
- Deregistration delay
- Slow start mode
- Automatic Target Weights
- Routing algorithms
- ...
ASG
La charge de nos applications peut varier au cours du temps, un ASG, Auto Scaling groups, est la ressource permettant d'adapter facilement le nombre de nos instances en fonction des besoins.
On parle de :
scale outquand on ajoute des instancesscale inquand on diminue le nombre d'instances
Ainsi, on peut consommer au plus juste les resources cloud éviter des coûts inutiles et du gâchi de resources. Un ASG permet aussi de répartir nos instances sur nos différentes zones. Il ajoute et enlève automatiquement les instances qu'il gère dans les target group de nos ELBs afin de renvoyer le traffic dessus.
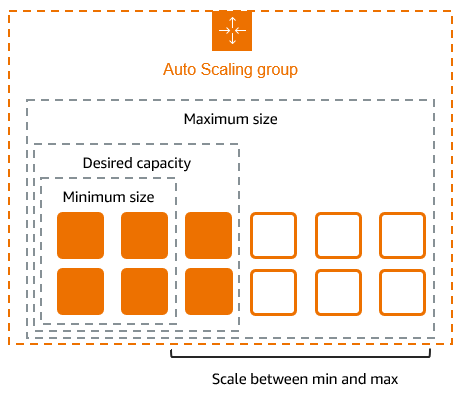
On spécifie plusieurs paramètres comme le nombre d'instances minimum et maximum qui définissent donc les bornes de
l'ASG.
On peut aussi définir une taille désirée qui garantira un nombre fixe, ou bien des scaling policies pour rendre le
nombre dynamique.
Les instances sont créées à partir d'un template, aussi appellé Launch Template qui contient donc les paramètres qu'auront les instances créées par l'ASG.
Note
Vous pourrez peut-être entendre parler de Launch configuration mais ils sont dépréciés au profit des Launch template
Health checks
On peut spécifier des health checks pour l'ASG ou se servir de ceux des targets group de notre ELB.
Un ASG permet ensuite d'automatiquement remplacer les instances qui n'iraient pas bien. On parle alors d'auto-healing.
Scaling policies
Un ASG permet d'adapter le nombre d'instances de plusieurs manières.
- De façon fixe via le
desired capacity. - De façon dynamique via les
Dynamic scaling policies. Cela se base sur des métriques et alarmesCloudwatch, le service de monitoring AWS. Celles-ci sont de 3 types différents :target tracking scalingpour suivre métrique à la manière d'un thermostatstep scalingpour augmenter et diminuer par paliers configurables. Par exemple si on dépasse de peu +1 sinon +2simple scalingpour faire un changement simple puis attendre avant de revérifier
- De façon prédite via les
Predictive scaling policies. L'ASG se base sur les anciennes métriques pour prédire l'usage et anticiper le scaling. Idéalement utilisé aussi avec du dynamique et quand la charge est prévisibles.
Il existe aussi des Scheduled actions permettant plutôt de planifier de façon récurrente ou one-shot.
Par exemple pour un black friday, vente de PS6, etc.
Note
Il existe bien sûr encore beaucoup de configurations possibles :
- Multiples types d'instance et options d'achats
- Remplacement automatique des Instances Spot
- Mise à jour des instances
- Hooks sur le cycle de vie des instances
- Warm pool
- ...
TP
À vous de jouer
Le but de cette étape est de remplacer nos deux instances de frontend et backend, chacune, par des instances créées par un ASG dans deux zones sur lesquelles un Application Load Balancer renvoie les requêtes.

Nous allons nous servir de notre module/abstraction compute pour éviter les répétitions.
- Copiez votre dossier précédent en un nouveau dossier nommé Step4
- Remplacez votre instance par un launch template
via
aws_launch_template
- N'y définissez plus les subnets ils seront donnés par l'ASG
- Déclarez votre ALB
avec
aws_lb.
load_balancer_type = "application"pour avoir un ALB- Le mettre
internet-facing
via le paramètre
internal = falseet dans des subnets publiques
- Déclarez votre target group
avec
aws_lb_target_group.
- Pour les healthcheck utilisez
/actuator/healthpour le backend et/healthpour le frontend
- Pour les healthcheck utilisez
- Déclarez le listener de l'ALB avec aws_lb_listener qui pointera sur le target group par défault
- Déclarez votre ASG
via
aws_autoscaling_group
- Utilisez le launch template précédemment créé
- Mettez un min/max/desired à 2
- Faites pointer les deux entrées DNS maintenant en alias sur les load balancer associés
Note
Vous pouvez au passage enlever les aws_ebs_volume et aws_volume_attachment qui n'ont plus lieux d'êtres maintenant que notre persistence se fait via une instance RDS!
Warning
Votre aws_launch_template doit bien encoder ses user_data en base64.
Pensez bien à mettre les load balancer en internet-facing via le paramètre internal = false.
Plus de détails
ici.
Success
Vous avez désormais une meilleure résilience et scalabilité !
Bonus
Sécurité
Nous pouvons maintenant mettre uniquement nos loadbalancer dans les subnet publiques et mettre toutes les instances créées dans les subnets privés. Nous pouvons aussi modifier/ajouter des security groups afin qu'uniquement les ALB puissent joindre les instances.
Par commodité, vous pouvez laisser les fronts dans le subnet public afin de s'en servir comme bastion si besoin.
Finops
Pour économiser le surcoût d'un ALB, ~230€ sur un an sur la région de Paris, faites en sorte de n'en utiliser qu'un seul.
Vous pourrez, à la place, vous appuyer sur les rules/listeners pour le routing et SNI pour les certificats.